九游会J9因为正本比它更擅长轻量任务的低功耗能效核如故被砍了-九游会j9·游戏「中国」官方网站

新酷居品第一期间免费试玩九游会J9,还有稠密优质达东谈主共享独有生涯训诲,快来新浪众测,体验各边界最前沿、最意旨、最佳玩的居品吧~!下载客户端还能赢得专享福利哦!
前两天托尼不是刚跟全球聊完格外 YES 的 AMD 在台北 Computex 大会上带来的新品嘛。
自古 “ 红蓝出 CP ” ,这不 AMD 刚整完,老党羽英特尔也来了。
是的,就在昨天,英特尔带着我方的最新转移端处理器架构也蹦哒着出来了——这才刚过了 8 个月,英特尔又发新架构了,况且看起来是有史以来最大的一次英特尔转移端架构升级。
看来蓝厂亦然的确被高通和苹果给卷怕了。
此次的新架构叫 Lunar Lake ,为了通俗全球操心,咱们干脆叫它 “ 月亮湖 ” 吧。
留给英特尔的湖( Lake )如故未几了

按英特尔我方的说法是,此次发布的 “ 月亮湖 ” 架构,是特地给条记本这样的转移建设上的处理工具的,至于台式机处理工具的架构 Arrow Lake ( 我可爱叫它箭湖 ),会在本年 9 月发布。
是以想我方攒主机的差友们,稍安勿躁,此次咱们先望望条记本上的情况。
这一波 Lunar Lake 的新架构发布活动,托尼有幸参与了英特尔的闭门媒体宣传会,提前了解到了许多新架构的技巧细节。
这里插一嘴隐微吐槽一下,英特尔的这个媒体宣传会整整开了五个小时!

好在这五个小时莫得空费,扫数看下来之后托尼对 “ 月亮湖 ” 这个新架构也有了一个基本的分解。如若让我一句话来评价这个新架构的话,那即是:
英子,你此次的确够知道,但些许也有点冷凌弃了。
全球听我讲完此次 “ 月亮湖 ” 比较上一代 Meteor Lake 的升级点就明白了。
率先我以为英特尔此次最最最最知道的升级,莫过于终于运行让台积电来给我方代工了!Lunar Lake 用上了台积电 N3B 和台积电 N6 两种工艺。
英特尔近几年,诚然有将 GPU 芯片以及处理器 SoC 当中部老实核交由台积电代工,然而重要的 CPU 中枢基本如故由英特尔我方制造。
然而奈何自家的工艺,着实是不争光,就连 CEO 基辛格也不得不承认,台积电领有更好的制程技巧,让台积电代工 “ 月亮湖 ” 的 CPU 中枢,是个更好的聘任。
台积电的威力怎样,不必我多说了吧,夸张少量说几乎即是各家厂商处理器芯片的春药。
有了台积电的加成,加上 GPU 升级了新的 Xe2 架构, “ 月亮湖 ” 的图形性能相较于上一代晋升了 50% ,披露方面也有了昭彰的升级;NPU 的 AI 算力更是翻了 4 倍。
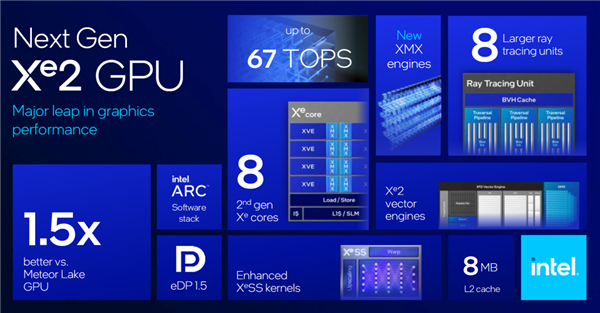
除了好意思好意思拥抱台积电以外,本年必考表情 AI 算力上, “ 月亮湖 ” 新架构也涓滴不璷黫, NPU 算力来到了 48 TOPS 。但不如 AMD 刚发布的 50 TOPS 算力的 Ryzen AI 。
天然啦,就 2 TOPS 的算力差距也不必那么严格,归正这两个难兄难弟总算是知足微软给 AIPC 定下的算力条目( 40 TOPS )了。
这下英特尔终于不必驰念闹见笑,不错释怀吹 “AIPC” 的意见了。

扯远了,咱们陆续纪念讲英特尔的新架构。
有了 NPU 的 AI 算力升级,再算上 GPU 、 CPU 的 AI 算力, “ 月亮湖 ” 的详细 AI 算力来到了 120 TOPS ,远远特别了上一代的 34 TOPS 。
在赢得这样强悍强的性能的同期, “ 月亮湖 ” 举座的功耗比较上一代却下落了 40% 。

不外我得指示全球,这些都是英特尔给的官方数据,施行表露奈何样,还得等新架构的处理器作念到了电脑上,咱们体验过才好下定论。
但很昭彰,英特尔此次更强了也更省电了。
是奈何作念到的?除了用上了台积电工艺以外,还有莫得别的原因?
这就要提到此次英子另一个很知道的场所——用上了愈加干练的算计单位( Compute Tile )架构,唐突说 CPU 架构。
上一代,英子的 CPU 用的如故 6+8 的中枢架构,也即是 6 个性能中枢( Performance Core )、 8 个能效中枢( Efficient Core ),另外皮 CPU 以外还会有 2 个低功耗能效中枢( Low Power Efficent Core )。

光是这一堆花里胡梢的名字,听起来就头疼了,更何况要把它们都调好。
英特尔我方推断也意志到了这个问题,是以成功在此次的 “ 月亮湖 ” 上大手一挥,把 6 + 8 + 2 一堆东倒西歪的层级给精简了。
成功改用了 4 个性能中枢 + 4 个能效中枢的架构。

砍中枢这个动作,看着是倒吸牙膏的嫌疑,但施行上,新的这 8 个中枢要比之前的强得多。
就拿此次的能效中枢来说,因为正本比它更擅长轻量任务的低功耗能效核如故被砍了,低负载下的功耗表露就只可指望它了。
而新的能效中枢表露格出门色,无论是单线程如故多线程的轻量任务,它都处理得格外好,能效比暴杀上代的低功耗能效核。
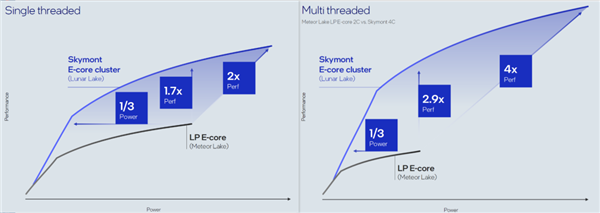
同期,正本不该它管的性能,它也表露的格出门色——当作一个专注于低功耗的中枢,性能反而要比上一代特地严防肠能的中枢要强出 2% 。
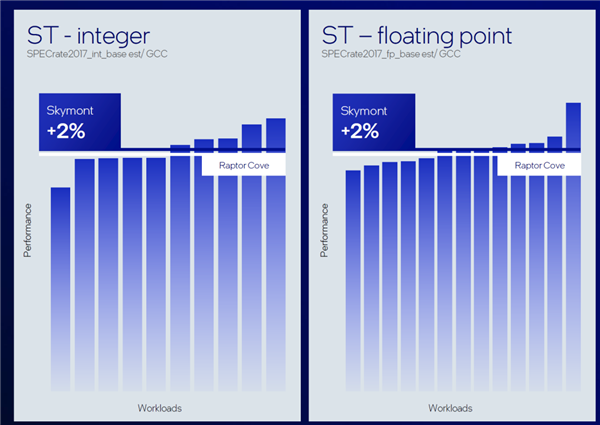
另外一类中枢,性能核,也很争光。新的性能核相较于上一代平均晋升 14% 。
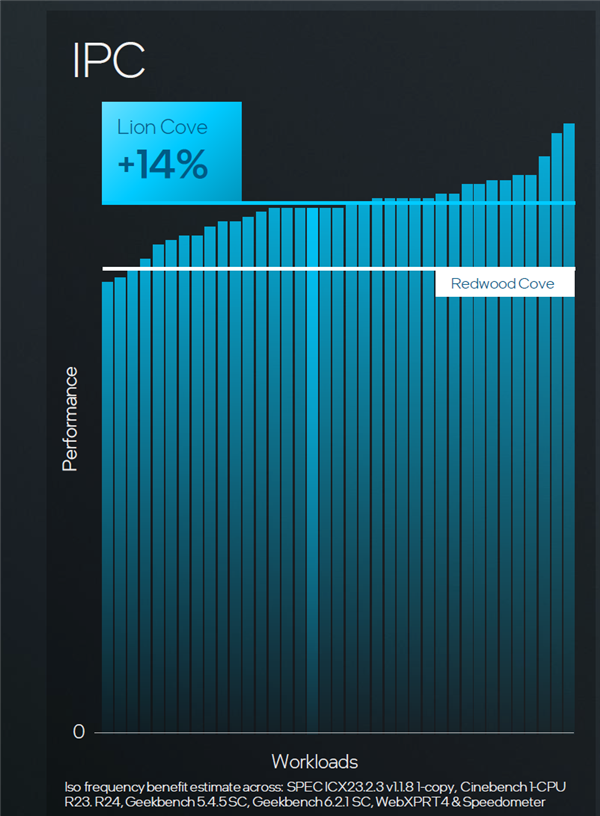
深嗜即是说,砍完中枢之后,不但结构愈加表示,更通俗软件系统去迁徙。同期每一类中枢自身也变得更强了。
OK ,聊收场新架构在 CPU 上的知道操作,咱们再来望望英特尔此次另一个 “ 知道 ” 的升级。此次的处理器,他长这样:

看不清不要紧,我给你们再放大一下——

你们看到没,英子这回向果子看皆了!
为了用更低的功耗达成更高的性能,英特尔也把正本插在主板上的内存条,作念到了处理器内部。
英特尔还给这个作念法起了个我方的名字,叫 Memory on Package 。同期提供 16GB 和 32GB ( 双通谈 ) LPDDR5X 两种成就。
还行,至少起步不是 8GB 。。。

这个作念法好不好,业界内和闲居用户一直都在争论。具体奈何评价,如故得从锋利两个方面来分析。
咱们先看克己吧。
小学二年事的算计机课上咱们如故学过了,电脑的内存是用来暂时存放处理器正在膨胀的要津和连所有据的。
英特尔这样把内存成功作念到了处理器里头,最大的克己天然即是让处理器膨胀要津、读写数据的后果更高了。
这其实也好分解,每次处理器要用某个数据的时候,再也不必像之前那样,跑老远到外边主板上的内存去拿,天然也就更快了。

与此同期,处理器所需要的功耗也会更低,巧诈少量分解即是每次读写数据不必跑那么远的路了,也就不必毒害那么大的力气了。
那么,代价是什么?
这就要说到英特尔新架构 “ 冷情冷凌弃 ” 的场所了——用户一朝选择了某一个规格的处理器之后,基本上就没法我方更换内存了。
过去给条记本电脑换内存条的伙伴们,可能还要盘桓一下,是我方把内存条买纪念找个视频随着换呢,如故花点钱去线下维修点让师父惩办。
当今好了,不必纠结了,英特尔把路都堵上了。

以后内存万一出了什么问题,也没法单独修了,只可连着 CPU 通盘换掉。
这样搞下来,最祸患确天然即是可爱 DIY 条记本的小伙伴们,我方动手换内存的乐趣算是透彻被英特尔抢劫了。
提议以后全球买英特尔的簿子一定要想明晰,我方对内存大小的需求是些许,毕竟当今是信得过的买定离手了,买完后悔想换也换不了。
天然如若你唐突你身边的东谈主是华强北老铁,动动手就能给 CPU 开盖、徒手 16G 扩容成 32 G ,那当我没说。
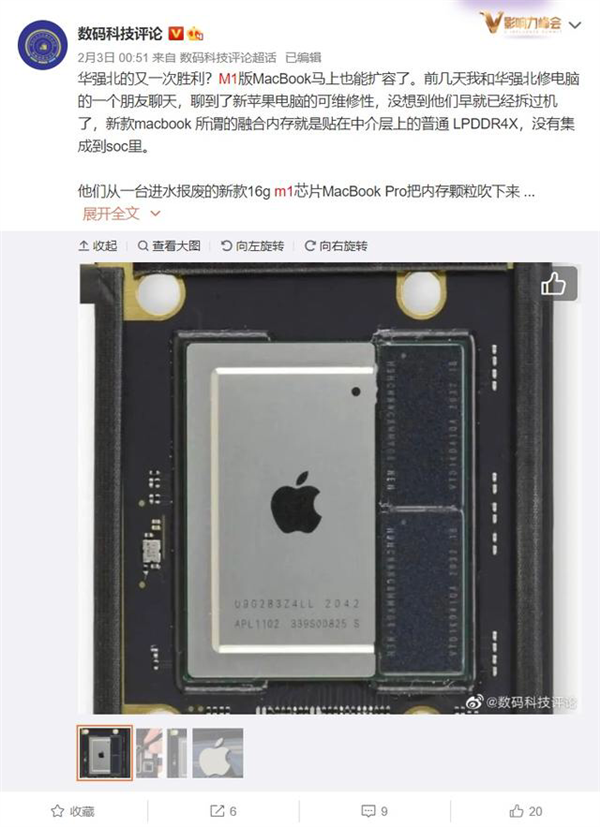
另外这个操作还会带来本钱问题。
为了把内存颗粒和处理器的其他模块封装在一个芯片里,英特尔必须给 “ 月亮湖 ” 架构的处理工具上愈加先进的封装。
这种内存和处理器放通盘的封装,本钱比以往要高了不少,英特尔会不会把这个这部分本钱转嫁到消费者头上,还得打一个问号。
归正苹果是这样干了,借着内存作念到处理器上,工艺、封装等等本钱会变高的契机,哐哐地把内存当金子卖。

OK 英特尔的新处理器架构,就给全球聊到这里。
这样盘下来会发现,英特尔此次的升级算得上是亮点多多了。从处理器举座架构到制程工艺,再到性能晋升,都可圈可点。
当作英特尔投入 AIPC 时间之后的第二代转移端处理器架构, Lunar Lake 的标的念念路也很表示。莫得只顾着大谈特谈 AI 和算力,关于跟闲居用户相关更良好的功耗、续航等等也格外的上心。
而跟近邻厂跟果子对皆,把内存作念到处理器内,这少量也格外的斗胆。虽说甘休掉了一部分用户的需求,但换来更好性能和更低的功耗,我以为如故合算的。
至于换来的这一部分克己有些许能给到条记本用户,可能还得让枪弹再飞顷刻间。英特尔把食材作念好了,但奈何把菜炒得厚味,就要看末端厂商们奈何去调教了。
累赘裁剪:随性著作内容举报九游会J9
]article_adlist--> 声明:新浪网独家稿件,未经授权辞谢转载。 -->